高级查询
聚合框架已经成为 MongoDB 进行批处理、实时分析、AI 检索的核心工具。本文在原有讲义基础上补充 6.x/7.x 新增的
$setWindowFields、$densify、$fill、Atlas Search、Vector Search 等能力,并提供常见场景模板。
聚合框架概述
MongoDB 聚合框架(Aggregation Framework)是一套对集合数据进行分阶段处理的计算管道:
- 可以作用在单个集合或多个集合(配合
$lookup/$unionWith) - 对输入文档执行一系列步骤(Stage),每个 Stage 会输出给下一个 Stage
- 常用于统计、数据清洗、维度分析、实时监控、AI 检索后处理
常见 Stage 与 SQL 对照:
| Stage | 作用 | SQL 对应 |
|---|---|---|
$match | 过滤 | WHERE |
$project / $set | 投影/新增字段 | SELECT ... AS |
$group | 分组聚合 | GROUP BY |
$sort | 排序 | ORDER BY |
$skip / $limit | 分页 | OFFSET/LIMIT |
$lookup | 左外连接 | LEFT OUTER JOIN |
$unwind | 展开数组 | UNNEST |
$bucket / $bucketAuto | 分桶 | GROUP BY + CASE |
$facet | 一次返回多个聚合结果 | 多个查询组合 |
$setWindowFields | 窗口函数 | OVER(PARTITION BY ...) |
$densify / $fill | 补齐时间序列 | 窗口分析 |
$unionWith | 合并集合 | UNION |
$vectorSearch* | 向量检索 | 向量相似度(Atlas/7.0+) |
$search* | 全文/语义搜索 | Atlas Search |
带 * 的 Stage 需在 Atlas 或 MongoDB 7.0+(含向量搜索模块)使用。
基本用法:
const pipeline = [
{ $match: { status: 'PAID' } },
{ $group: { _id: '$category', total: { $sum: '$amount' } } },
{ $sort: { total: -1 } }
];
db.orders.aggregate(pipeline, { allowDiskUse: true });
js
典型场景模板
1. 统计销售额与订单数量
db.orders.aggregate([
{ $match: { createdAt: { $gte: ISODate('2024-01-01') } } },
{
$group: {
_id: { month: { $month: '$createdAt' }, channel: '$channel' },
totalAmount: { $sum: '$amount' },
orderCount: { $count: {} }
}
},
{ $sort: { '_id.month': 1 } }
]);
js
2. $lookup 多集合关联
db.orders.aggregate([
{ $match: { status: 'PAID' } },
{
$lookup: {
from: 'customers',
localField: 'customerId',
foreignField: '_id',
as: 'customer'
}
},
{ $unwind: '$customer' },
{ $project: { amount: 1, 'customer.name': 1, 'customer.level': 1 } }
]);
js
3. 数组处理 $unwind

db.blog.aggregate([
{ $unwind: '$tags' },
{ $group: { _id: '$tags', usage: { $count: {} } } },
{ $sort: { usage: -1 } }
]);
js
4. 分桶 $bucket
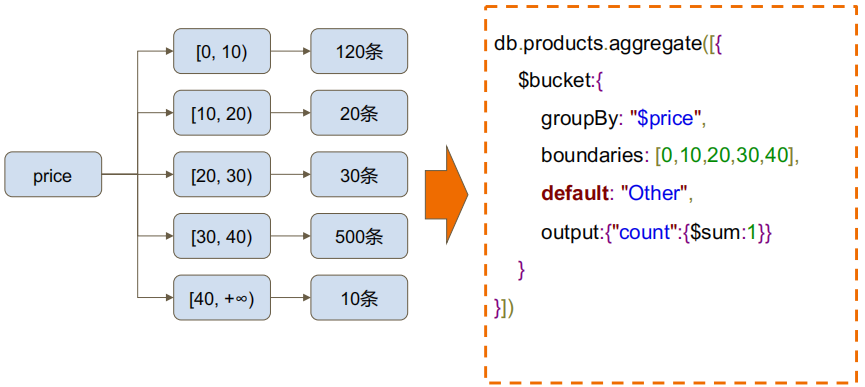
db.students.aggregate([
{
$bucket: {
groupBy: '$score',
boundaries: [0, 60, 80, 90, 100],
default: 'other',
output: {
count: { $count: {} },
names: { $push: '$name' }
}
}
}
]);
js
5. 多面结果 $facet
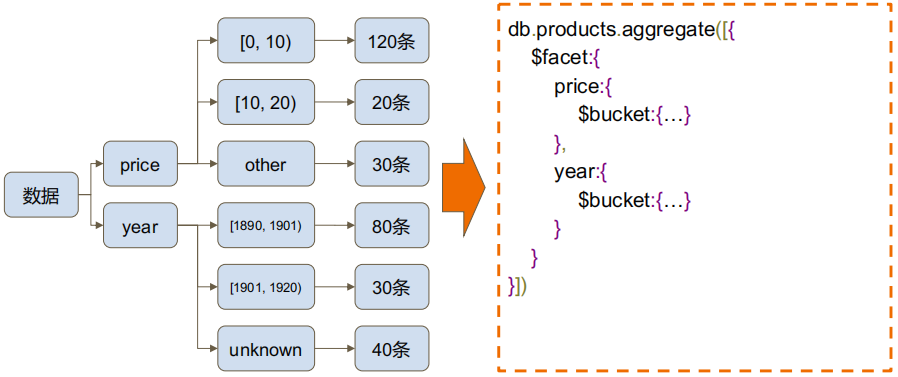
db.products.aggregate([
{
$facet: {
topSales: [
{ $sort: { sales: -1 } },
{ $limit: 5 }
],
priceRange: [
{
$bucketAuto: {
groupBy: '$price',
buckets: 4,
output: { count: { $count: {} } }
}
}
]
}
}
]);
js
6. 时间序列补齐 $densify + $fill
db.metrics.aggregate([
{ $match: { metric: 'cpu' } },
{ $densify: { field: 'timestamp', range: { step: 1, unit: 'minute' } } },
{ $fill: { sortBy: { timestamp: 1 }, output: { value: { method: 'linear' } } } }
]);
js
7. Atlas Search + 向量检索(AI 场景)
db.articles.aggregate([
{
$search: {
index: 'default',
compound: {
must: [{ text: { query: 'MongoDB replication', path: ['title', 'body'] } }]
}
}
},
{
$vectorSearch: {
index: 'article-embedding',
path: 'embedding',
queryVector: queryEmbedding,
numCandidates: 150,
limit: 5
}
},
{ $project: { title: 1, score: { $meta: 'searchScore' } } }
]);
js
性能与调优
- 使用
db.collection.aggregate(pipeline).explain('executionStats')查看执行计划 - 对
$match、$group、$lookup关键字段建立索引,减少内存占用 - 长管道开启
allowDiskUse: true,避免超过 100MB 内存限制 - 监控
mongostat、mongotop或 Atlas Profiler,识别慢 Stage - 对实时任务可结合
$merge写回结果,或利用changeStream构建持续计算
推荐资料
- MongoDB 官方文档 - Aggregation Pipeline
- Aggregation Pipeline Builder(Compass/Atlas 内可视化调试)
- MongoDB World / .local 近年分享:Columnstore Index、Vector Search、AI RAG 实战
牢记:将尽可能多的数据准备工作放在聚合管道中完成,可以显著降低应用层负担,并可复用在 Analytics、BI、LLM 等多种场景。